Publications or Manuscripts
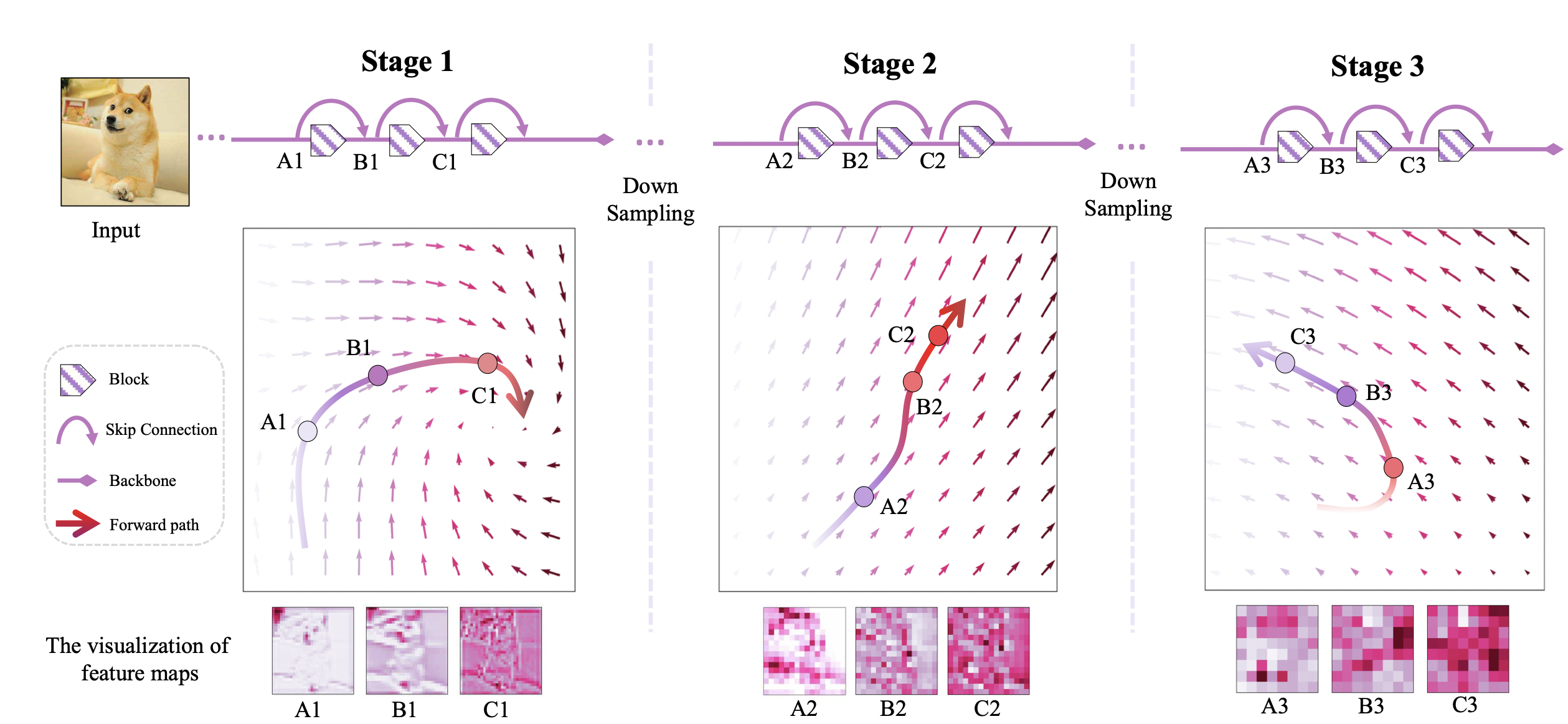
A Generic Shared Attention Mechanism for Various Backbone Neural Networks
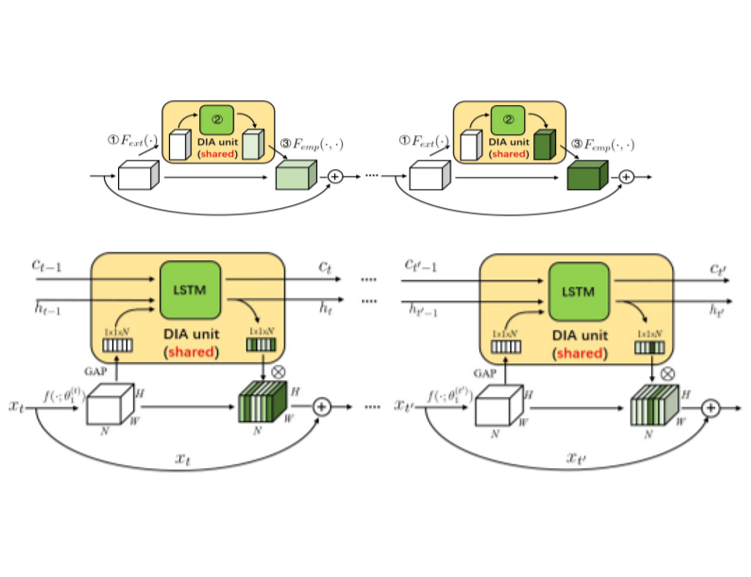
Dense-and-Implicit Attention shares SAMs across layers and uses LSTM to bridge correlations, improving efficiency, regularization, and performance across tasks like classification, detection, and generation.
Z. Huang, S. Liang, M. Liang, Nuerocomputing, 2024, 128697, [PDF, Code].
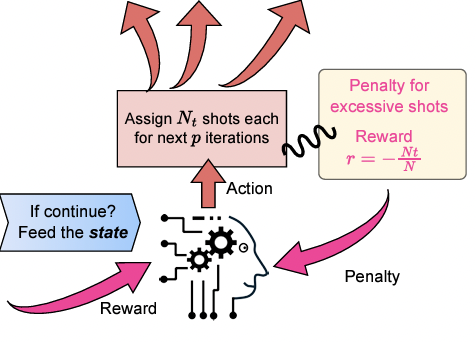
(2024) Artificial-Intelligence-Driven Shot Reduction in Quantum Measurement
The paper proposes a reinforcement learning approach to optimize shot allocation in Variational Quantum Eigensolver for approximating molecular ground state energies. The RL agent learns shot assignment policies across VQE iterations to minimize total shots while achieving convergence, reducing reliance on hand-crafted heuristics.
S. Liang, L. Zhu, C. Yang, X. Li, Chemical Physics Reviews, accepted [PDF, Code].
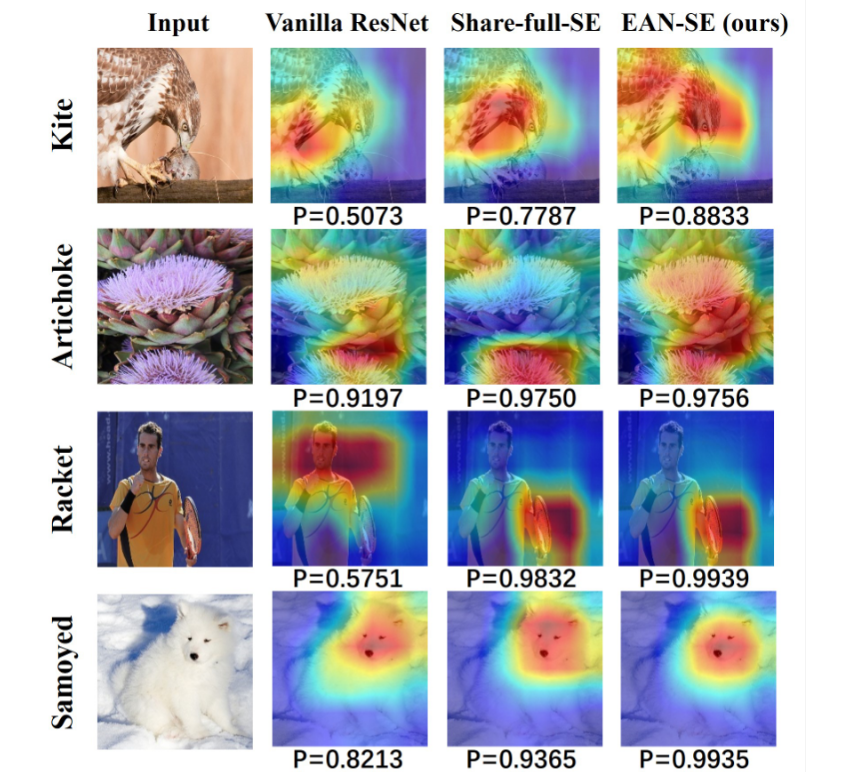
(2024) Lottery Ticket Hypothesis for Attention Mechanism in Residual Convolutional Neural Network
To improve the efficiency for the existing attention modules, we leverage the sharing mechanism to share the attention module within the backbone and search where to connect the shared attention module via reinforcement learning.
Z. Huang, S. Liang, M. Liang, W. He, H. Yang, L Lin, (Joint first) IEEE International Conference on Multimedia and Expo [PDF, Code].
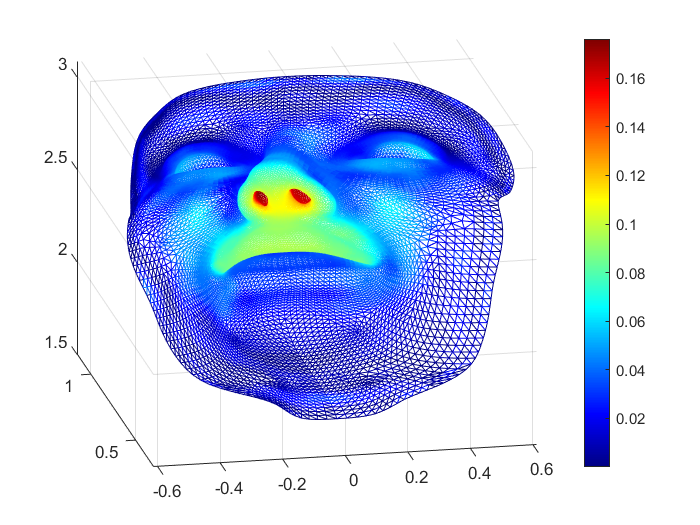
(2024) Solving PDEs on Unknown Manifolds with Machine Learning
We propose a mesh-free computational framework and machine learning theory for solving elliptic PDEs on unknown manifolds, identified with point clouds, based on diffusion maps (DM) and deep learning.
S. Liang, S. Jiang, J. Harlim, H. Yang, Applied and Computational Harmonic Analysis [PDF, Code].
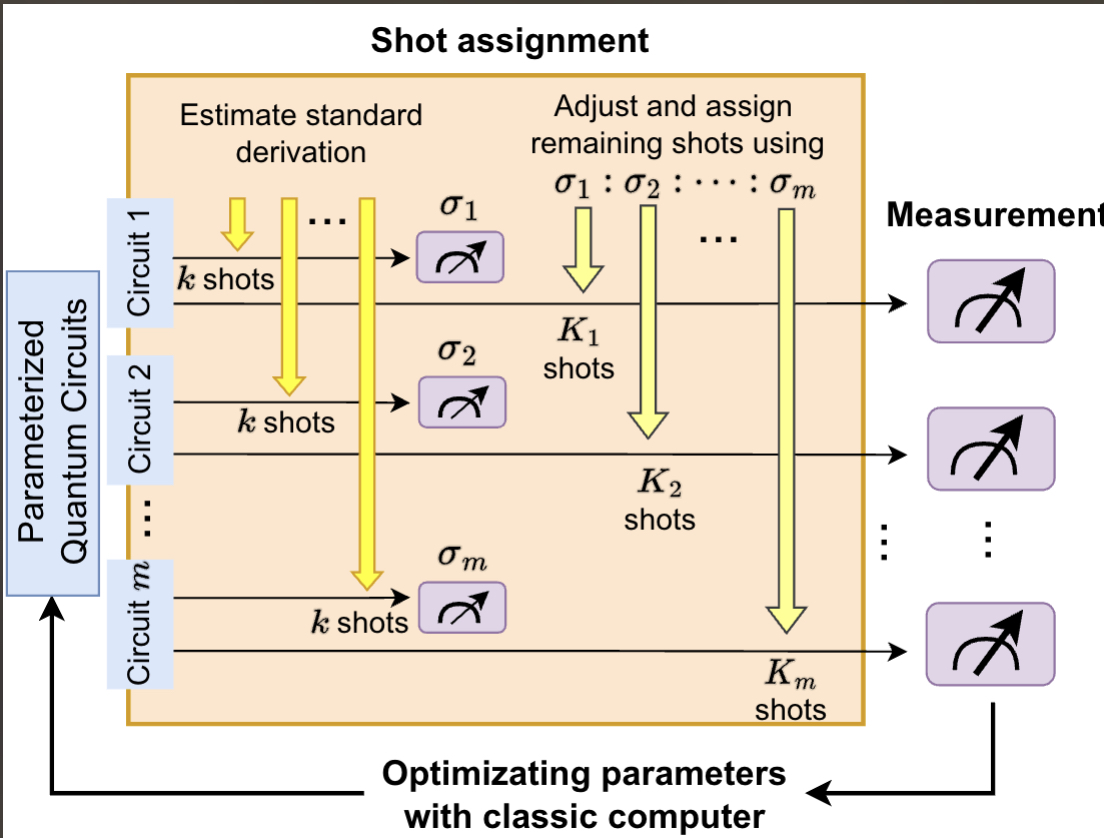
(2024) Optimizing Shot Assignment in Variational Quantum Eigensolver Measurement
This work introduces two shot assignment strategies based on estimating the standard deviation of measurements to improve the convergence of VQE and reduce the required number of shots. These strategies specifically target two distinct scenarios: overallocated and underallocated shots.
L Zhu, S Liang, C Yang, X Li, (Joint first) Journal of Chemical Theory and Computation [PDF, Code].
(2024) Reproducing Activation Function for Deep Learning
We propose reproducing activation functions which employs several basic functions and their learnable linear combination to construct neuron-wise data-driven activation functions for each neuron.
S. Liang, L. Lyu, C. Wang, H. Yang, Communications in Mathematical Sciences [PDF, Code].
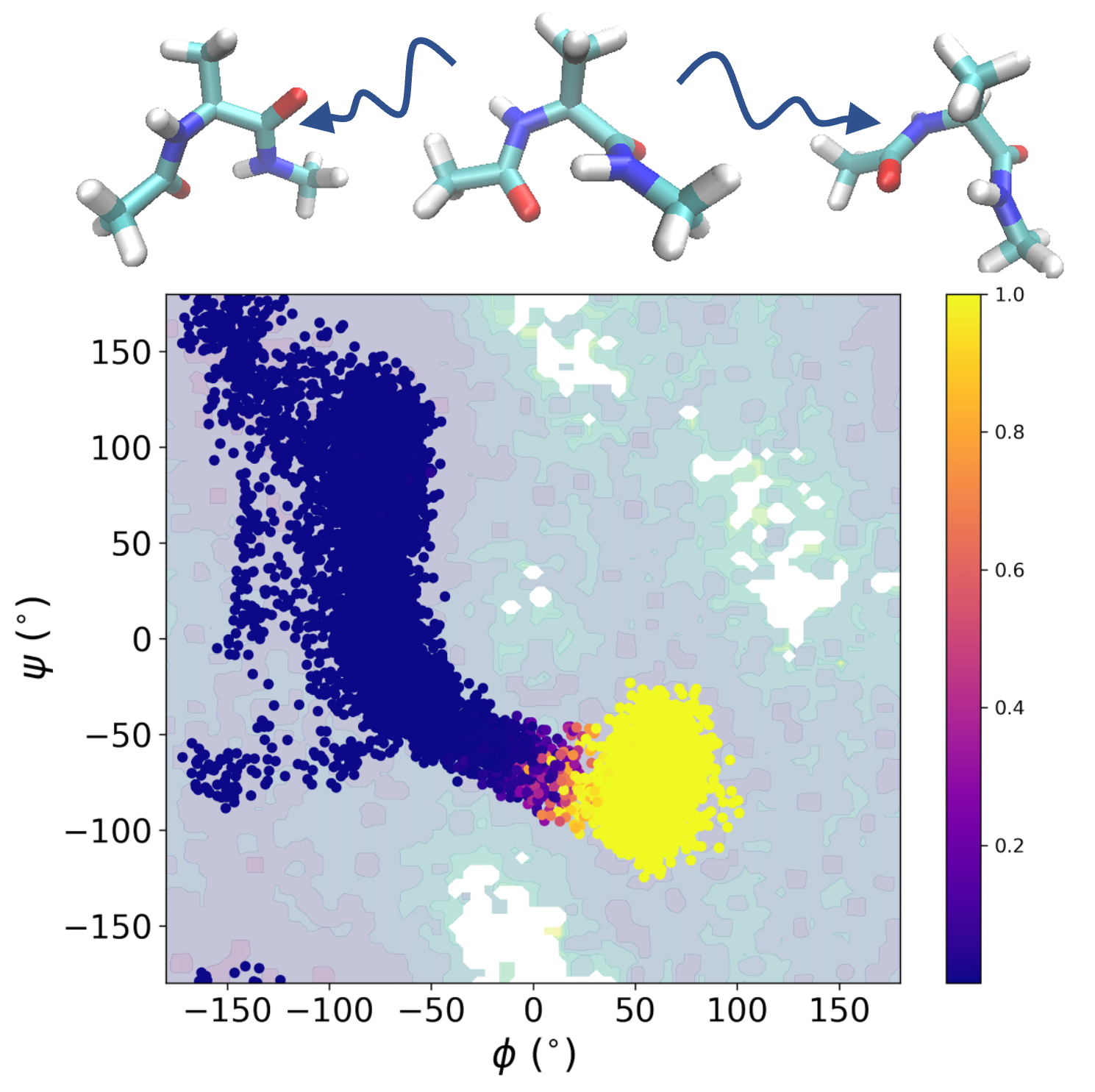
(2023) Probing reaction channels via reinforcement learning
We propose a RL-based method to generate important configurations that connect reactant and product states along chemical reaction paths. These configurations can be effectively employed in a NN-PDE solver to obtain a solution of Backward Kolmogorov equation, even when the dimension of the problem is very high.
S Liang, AN Singh, Y Zhu, DT Limmer, C Yang, Mach. Learn.: Sci. and Tech. [PDF, Code].
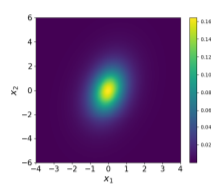
(2023) Stationary Density Estimation of Itô Diffusions Using Deep Learning
We propose a deep learning scheme to estimate the density from a discrete-time series that approximate the solutions of the stochastic differential equations. We establish the convergence of the proposed scheme.
Y. Gu, J. Harlim, S. Liang, H. Yang, SIAM Journal on Numerical Analysis (Corresp. author) [PDF].
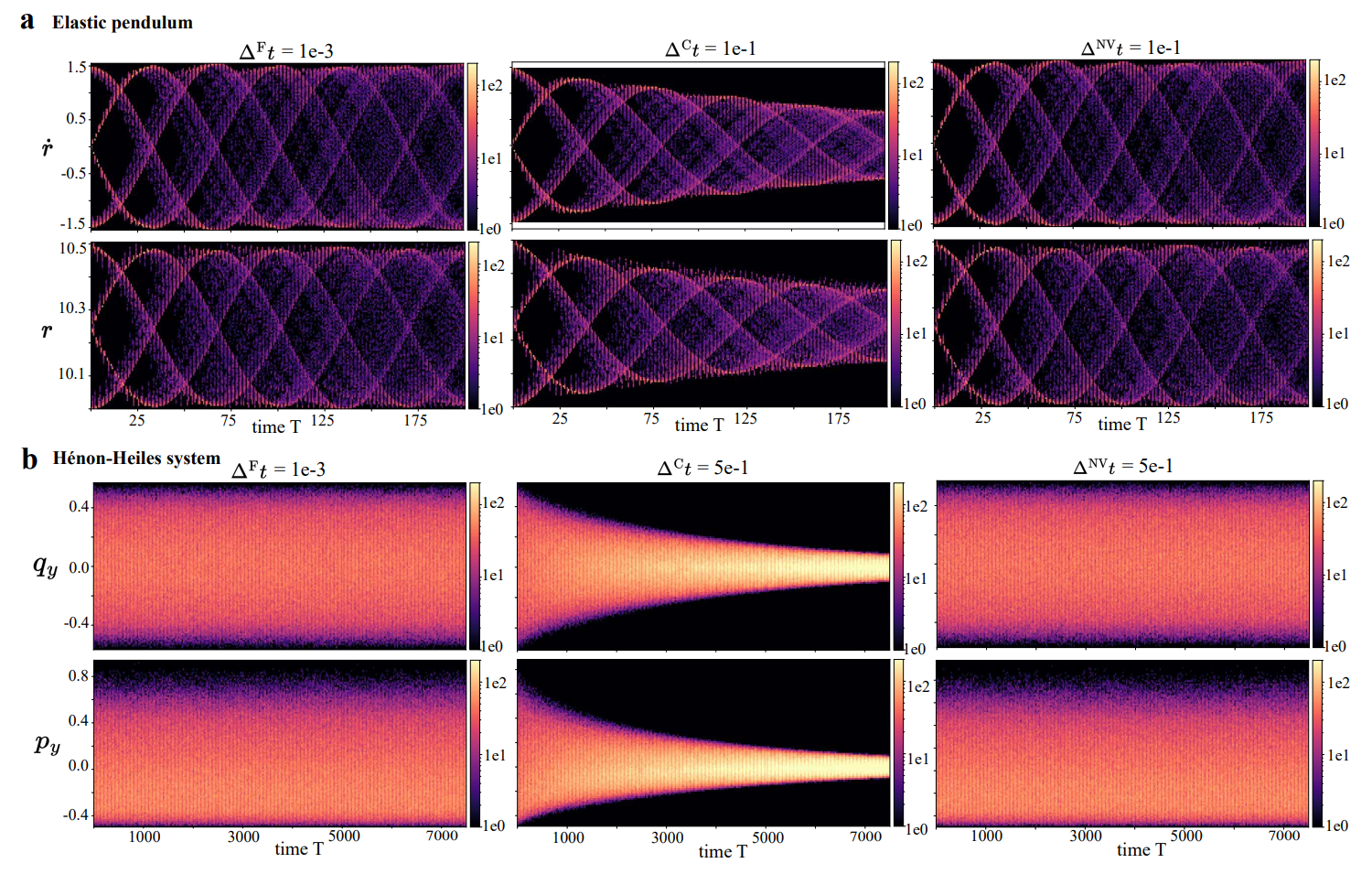
(2022) On Fast Simulation of Dynamical System with Neural Vector Enhanced Numerical Solver
We propose a data-driven corrector method that allows using large step sizes while compensating for the integration error for high accuracy.
Z. Huang, S. Liang, H. Zhang, H. Yang, L. Lin, To appear in Scientific Reports (Joint first) [PDF, Code].
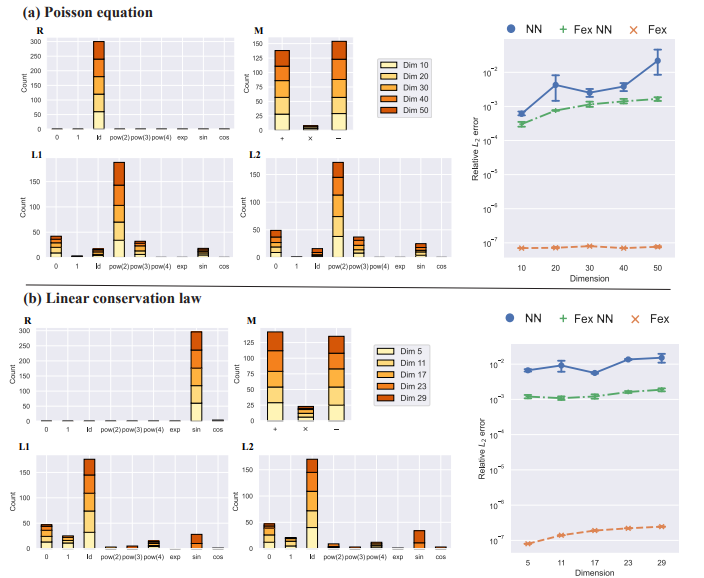
(2022) Finite Expression Method for Solving High-Dimensional Partial Differential Equations
We introduce a new methodology that seeks an approximate PDE solution in the space of functions with finitely many analytic expressions and, hence, this methodology is named the finite expression method (FEX).

(2022) Quantifying spatial homogeneity of urban road networks via graph neural networks
We borrow the power of graph neural networks to model the road network system and use its predictability to quantify the spatial homogeneity. The proposed measurement is shown to be a non-linear integration of multiple geometric properties. We demonstrate its connection with the road irregularity and the socioeconomic status indicators.
J. Xue, N. Jiang, S. Liang, Q. Pang, T. Yabe, S. Ukkusuri, J. Ma, Nature Machine Intelligence, 4, 246–257 (2022) [PDF, Code].
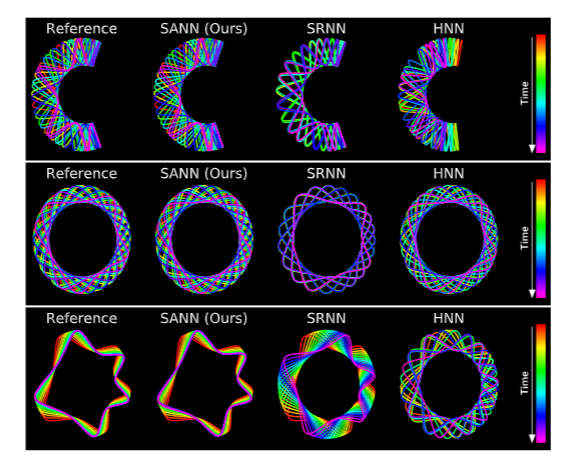
(2021) Stiffness-aware neural network for learning Hamiltonian systems
We propose stiffness-aware neural network, a new method for learning stiff Hamiltonian dynamical systems from data. SANN identifies and splits the training data into stiff and nonstiff portions based on a stiffness-aware index, a metric to quantify the stiffness of the dynamical system.
S. Liang, Z. Huang, H. Zhang, ICLR 2022 [PDF].
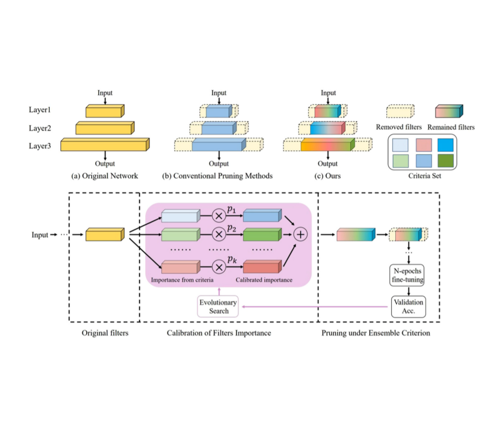
(2021) Blending Pruning Criteria for Convolutional Neural Networks
We propose a novel framework to integrate the existing filter pruning criteria by exploring the criteria diversity. The proposed framework contains two stages: Criteria Clustering and Filters Importance Calibration.
W. He, Z. Huang, M. Liang, S. Liang, H. Yang, ICANN 2021 [PDF].
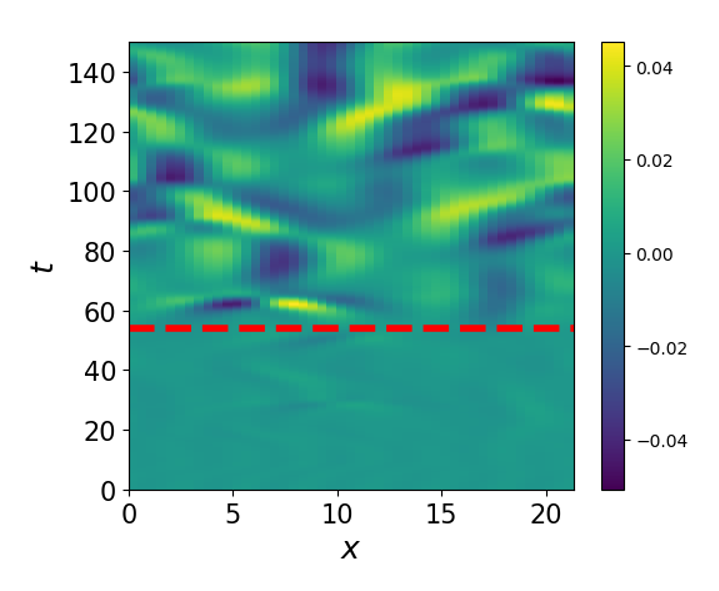
(2019) Machine learning for prediction with missing dynamics
We propose a framework that reformulates the prediction problem as a supervised learning problem to approximate a map that takes the memories of the resolved and identifiable unresolved variables to the missing components in the resolved dynamics.
J. Harlim, S. Jiang, S. Liang, H. Yang, J. Comput. Phys., (Alphabetical order) [PDF].
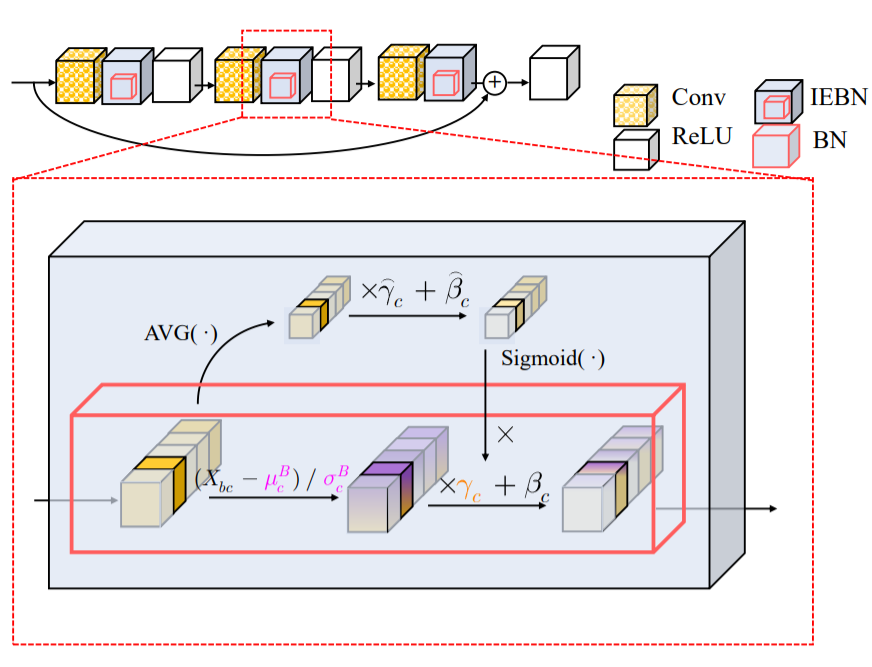
(2019) Instance Enhancement Batch Normalization: An Adaptive Regulator of Batch Noise
We point out that self-attention mechanism can help to regulate the noise by enhancing instance-specific information and propose a normalization that recalibrates the information of each channel by a simple linear transformation.
S. Liang, Z. Huang, M. Liang, H. Yang, AAAI-2020 [PDF, Code].
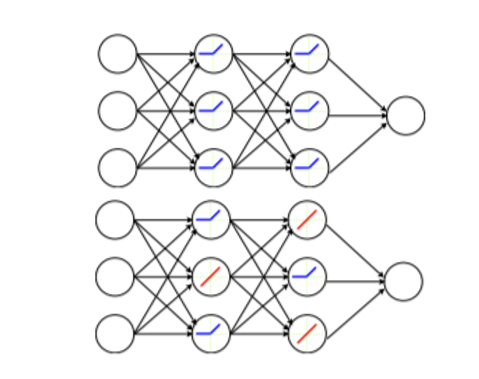
(2018) Drop-activation: Implicit parameter reduction and harmonic regularization
We propose a regularization method that drops nonlinear activation functions by setting them to be identity functions randomly during training time.
S. Liang, Y. Khoo, H. Yang, Communications on Applied Mathematics and Computation [PDF, Code].